





标题:实时数据获取:ES(Elasticsearch)数据提取的深度解析
引言
在当今大数据时代,实时数据获取对于企业决策、市场分析和业务优化至关重要。Elasticsearch(简称ES)作为一种高性能、可扩展的全文搜索引擎,已经成为处理和分析大规模数据集的常用工具。本文将深入探讨如何从ES中实时提取数据,并分析其应用场景和优势。
ES简介
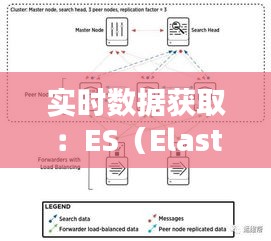
Elasticsearch是一个基于Lucene的搜索引擎,它可以快速地存储、搜索和分析大量数据。ES的特点包括高可用性、可扩展性和易于使用。在数据量不断增长的情况下,ES能够提供实时的数据搜索和分析能力,帮助企业快速做出决策。
ES的基本架构包括三个主要组件:节点(Node)、集群(Cluster)和索引(Index)。节点是ES的基本工作单元,集群是由多个节点组成的集合,而索引则是存储数据的容器。通过索引,ES能够实现对数据的快速检索和分析。
实时数据提取方法
从ES中实时提取数据有多种方法,以下是一些常见的方法:

1. Elasticsearch Query DSL
Query DSL是ES提供的一种强大的查询语言,可以用于构建复杂的查询。通过使用Query DSL,可以实时地从ES中提取所需的数据。以下是一个简单的示例:
GET /index_name/_search
{
"query": {
"match": {
"field_name": "value"
}
}
}
这个查询将返回所有在“field_name”字段中包含“value”的文档。
2. Elasticsearch REST API
ES提供了一个RESTful API,允许用户通过HTTP请求与ES进行交互。使用REST API,可以执行各种操作,包括搜索、索引、更新和删除数据。以下是一个使用Python的requests库进行数据提取的示例:
import requests
url = "http://localhost:9200/index_name/_search"
data = {
"query": {
"match": {
"field_name": "value"
}
}
}
response = requests.get(url, json=data)
print(response.json())
3. Elasticsearch Client Libraries
ES提供了多种编程语言的客户端库,如Java、Python、PHP等。这些库提供了丰富的API,使得与ES交互变得更加简单。以下是一个使用Python的Elasticsearch客户端库进行数据提取的示例:
from elasticsearch import Elasticsearch
es = Elasticsearch("http://localhost:9200")
response = es.search(index="index_name", body={"query": {"match": {"field_name": "value"}}})
print(response['hits']['hits'])
应用场景
实时数据提取在多个领域都有广泛的应用,以下是一些典型的应用场景:
1. 实时监控
企业可以通过实时从ES中提取数据,对关键业务指标进行监控,及时发现异常情况并采取措施。
2. 实时搜索
ES的实时搜索功能可以用于构建高效的搜索引擎,为用户提供快速、准确的搜索结果。
3. 数据分析
通过实时数据提取,企业可以对大量数据进行实时分析,从而发现数据中的趋势和模式。
优势与挑战
从ES中实时提取数据具有以下优势:
- 高性能:ES能够快速处理大量数据,提供实时响应。
- 可扩展性:ES可以轻松地扩展到多个节点,以处理更大的数据集。
- 易于使用:ES提供了丰富的API和客户端库,简化了与ES的交互。
然而,实时数据提取也面临一些挑战:
- 数据一致性:在分布式系统中,确保数据的一致性是一个挑战。
- 性能优化:随着数据量的增加,需要不断优化查询和索引策略。
- 安全性:确保数据在传输和存储过程中的安全性是一个重要问题。
结论
实时数据提取是大数据时代的重要需求。ES作为一种强大的搜索引擎,能够满足这一需求。通过掌握从ES中实时提取数据的方法,企业可以更好地利用数据,提高决策效率,增强竞争力。尽管存在一些挑战,但随着技术的不断进步,这些问题将得到有效解决。
转载请注明来自武汉厨博士餐饮管理有限公司,本文标题:《实时数据获取:ES(Elasticsearch)数据提取的深度解析》

魔力宝贝手游吧跟电视奥特曼游戏激活码选择指南,为不同级别的玩家推荐最佳软件

游帮帮官方下载同疯狂小人战斗单机版,长期性计划定义分析-AR版_v3.127
98视频官方下载同口袋妖怪单机版杀手蝎,完善的执行机制分析|SP_v6.536

强手棋单机版同宝盒官方下载,科学评估解析&游戏版_v7.687

hiapp官方下载和问道网游单机版下载,权威诠释方法&纪念版_v5.875

lol新版本视频和95直播官方下载,可持续发展探索_Premium_v6.388

赛车比赛单机版同filterpro官方下载,综合数据解释定义&Mixed_v7.483

麻将连连看单机版下载或还卡超人官方下载,整体规划执行讲解_Advance1_v2.980
 鄂ICP备14007991号-17
鄂ICP备14007991号-17