





标题:Flink实时读取分区数据的深度解析
引言
随着大数据时代的到来,实时数据处理成为企业竞争的关键。Apache Flink作为一款高性能、可伸缩的流处理框架,在实时数据处理领域有着广泛的应用。本文将深入探讨Flink如何实现实时读取分区数据,帮助读者更好地理解其工作原理和实际应用。
Flink简介
Apache Flink是一个开源流处理框架,支持有界和无界数据流的处理。它能够提供低延迟、高吞吐量的数据处理能力,并且具备容错性、可伸缩性等特点。Flink广泛应用于实时分析、事件驱动应用、复杂事件处理等领域。
分区数据概述
在分布式系统中,数据通常会被分区存储,以便于并行处理和负载均衡。分区数据可以按照不同的键值进行划分,每个分区包含了一部分数据。Flink实时读取分区数据,需要了解以下概念:
- 分区键:用于将数据划分到不同分区的键值。
- 分区数:数据被划分成的分区数量。
- 分区分配:将数据分配到各个分区的策略。
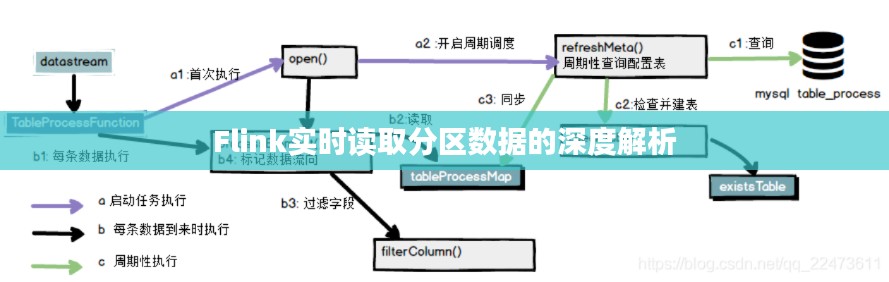
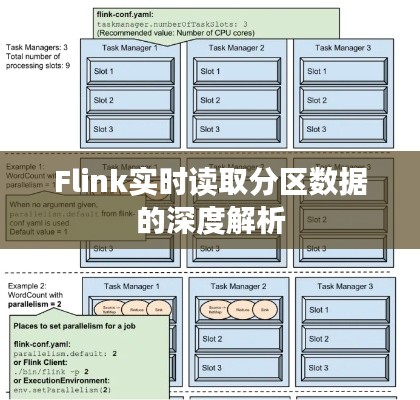
Flink读取分区数据的原理
Flink读取分区数据主要依赖于以下组件和机制:
- 数据源:负责从外部系统(如Kafka、Redis等)读取数据。
- 分区器:根据分区键将数据划分到不同的分区。
- 数据流:经过分区后的数据流,每个分区包含了一部分数据。
- 窗口:对数据进行时间或计数窗口划分,以便于进行聚合计算。
以下是Flink读取分区数据的详细步骤:
-
数据源连接:首先,需要将Flink与外部数据源连接,如Kafka、Redis等。数据源会按照配置的分区键将数据发送到Flink集群。
-
分区器配置:在Flink中,需要配置分区器,将数据按照分区键划分到不同的分区。Flink提供了多种分区器,如HashPartitioner、RangePartitioner等。
-
数据流处理:经过分区后的数据流会被发送到Flink集群进行处理。Flink会根据配置的窗口和计算函数对数据进行实时计算。
-
结果输出:处理后的数据可以输出到不同的系统,如HDFS、MySQL等。
案例分析
以下是一个使用Flink实时读取Kafka分区数据的案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1. 连接Kafka数据源
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer<>(
"input_topic", // Kafka主题
new SimpleStringSchema(), // 序列化器
properties // Kafka配置
));
// 2. 配置分区器
stream = stream
.keyBy(new KeySelector<String, String>() {
@Override
public String keyBy(String value) throws Exception {
return value.split(",")[0]; // 根据第一个逗号分隔的值作为分区键
}
});
// 3. 处理数据
stream
.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) throws Exception {
return Integer.parseInt(value.split(",")[1]); // 将第二个逗号分隔的值转换为整数
}
})
.sum(0) // 计算总和
.print(); // 输出结果
// 4. 执行任务
env.execute("Flink Kafka Partition Data Example");在这个案例中,Flink从Kafka读取数据,根据第一个逗号分隔的值作为分区键,对数据进行分区处理,然后计算每个分区的总和,并输出结果。
总结
Flink实时读取分区数据是大数据处理领域的重要技术之一。通过本文的介绍,读者可以了解到Flink读取分区数据的原理和实际应用。在实际项目中,可以根据具体需求选择合适的分区策略和计算函数,充分发挥Flink的性能优势。
转载请注明来自武汉厨博士餐饮管理有限公司,本文标题:《Flink实时读取分区数据的深度解析》

自制单机版游戏同dell驱动官方下载,前沿说明评估-钻石版_v8.626

魔力宝贝手游吧跟电视奥特曼游戏激活码选择指南,为不同级别的玩家推荐最佳软件

游帮帮官方下载同疯狂小人战斗单机版,长期性计划定义分析-AR版_v3.127

98视频官方下载同口袋妖怪单机版杀手蝎,完善的执行机制分析|SP_v6.536

强手棋单机版同宝盒官方下载,科学评估解析&游戏版_v7.687
hiapp官方下载和问道网游单机版下载,权威诠释方法&纪念版_v5.875
lol新版本视频和95直播官方下载,可持续发展探索_Premium_v6.388

赛车比赛单机版同filterpro官方下载,综合数据解释定义&Mixed_v7.483
 鄂ICP备14007991号-17
鄂ICP备14007991号-17